Indipendenza Strutturale della Conoscenza dal contesto di riferimento: il principio base più innovativo è senza dubbio quello che esprime l’indipendenza della conoscenza dalla struttura lessicale e dal particolare glossario dei termini utilizzato: la struttura della conoscenza non è legata al peculiare ambito applicativo, ovvero: i processi di ragionamento fautori di conoscenza non sono “figli unici di madre vedova”, ma seguono dinamiche trasversali e interdisciplinari che sono ripetitive secondo classi tipologiche che fanno parte di un sistema inerziale nel quale valgono universalmente i principi base della Natura e dell’uomo (v. Piramide dei Bisogni Primari di A.Maslow [20]), a prescindere dagli scenari tecnologici, politici e di mercato del momento. Un esempio per tutti di indipendenza strutturale della conoscenza: l’Ingegneria Biomedica è nata quando finalmente discipline diverse dal punto di vista lessicale e dei contenuti, come la medicina, la fisica, l’ingegneria, la biologia, ecc., si sono incontrate “interdisciplinarmente” nel suddetto sistema di riferimento inerziale, al fine di soddisfare un bene primario come quello della salute. L’esistenza di una struttura comune della conoscenza consente un’interazione più facile con nuove aree di conoscenza e favorisce lo sviluppo dell’approccio di ragionamento interdisciplinare o “Interdisciplinary Thinking” [7], in quanto anche trovandosi in un contesto nuovo di conoscenza, è possibile riconoscere la struttura (comune) di ragionamento di riferimento e adattarsi velocemente allo specifico lessico e al glossario dei termini utilizzato e infine, essere in brevissimo tempo pro-attivi fornendo il proprio contributo cognitivo.
Autore: Giovanni Mappa
Advisor per l'Innovazione d'Impresa
Computazione Non-Deterministica
Computazione Non-Deterministica: i Modelli Matematici possono essere considerati come un particolare sottoinsieme dei Modelli di Conoscenza, ma mentre nei primi si rappresenta la realtà dei fenomeni secondo procedimenti deterministici e subordinata in genere a delle ipotesi iniziali semplificative, nei modelli di conoscenza la realtà è rappresentata anche nella propria natura non-deterministica, attraverso un approccio sistemico e procedimenti che tengono conto della “naturale” incertezza nei dati e nelle informazioni, rispetto alla minimizzazione degli errori e alla ricerca di soluzioni di “buon senso” (common sense). Poniamoci infatti, la seguente domanda: nel ragionare e prendere ad es. una decisione, il nostro cervello risolve un sistema di equazioni o risolve per caso un’espressione algebrica? Certo che no. Allora forse c’è un “gap” tra quello che ci hanno insegnato a scuola nell’ambito delle computazione di dati (v. Matematica) e il modo “naturale” di computare informazioni proprie del nostro cervello e poi trasferito alle macchine (v. Intelligenza Artificiale). La computazione non deterministica ci consente di fare operazioni con le informazioni quali-quantitative anziché con i dati, ovvero con il contenuto informativo che i dati possono o meno esprimere. Un dato può essere considerato come un “insieme” che ha un contenuto informativo percentualmente differente a seconda del contesto e del target a cui è destinato. Ritornando all’esempio precedente sulle condizioni atmosferiche, un valore di temperatura dell’aria esterna di 15 °C rispetto alla scelta di vestirsi in maniera adeguata per uscire di casa fornisce una indicazione decisionale solo parziale (% certezza), se non è sovrapposta alle altre informazioni come ad es. la pressione atmosferica e l’umidità relativa. L’insieme risultante dall’intersezione dei tre insiemi di partenza ottenibile rispetto ad un target di “tempo di pioggia” o di “tempo soleggiato”, fornisce un valore % risultante di certezza più elevato rispetto a quello che ciascun dato di partenza può esprimere singolarmente: se consideriamo che la temperatura di 15°C rispetto al target “meteo-pioggia”, contribuisce per il 30%, mentre la pressione atmosferica per il 25% e l’umidità relativa per il 35%, si avrebbe che la decisione di vestirsi in un certo modo piuttosto che in un altro avrebbe un grado di certezza complessivo del 65,875% (somma insiemistica), che è superiore al 50% di soglia, anche se con ancora un 34,125% di % incertezza che potrebbe essere soddisfatto da un’altra “intersezione insiemistica” fornito da un ulteriore dato (ad es. dal valore della velocità del vento). Alle stesse conclusioni si potrebbe arrivare con dati differenti (v. es. millimetri di pioggia), sia in termini di contenuto informativo che numerici.
Modellazione Reticolare della Conoscenza
Modellazione Reticolare della Conoscenza: dal punto di vista logico, ogni modello di conoscenza è rappresentabile da una “cella informativa base” dotata di “n” dati/info in ingresso (input) e “m” meta-informazioni in output: all’interno della cella è possibile avere differenti relazioni di inferenza input/output: dalla semplice inferenza XY (curva di conoscenza n=1, m=1), fino a intere matrici “n*m” inferenziali. Gli “m” output di una cella possono a loro volta diventare in parte o in toto, input per un’altra cella e così via fino a realizzare una rete di celle in grado di elaborare un numero teoricamente infinito di informazioni.
Un processo tipico di “modellazione” della conoscenza, soprattutto nella realizzazione di sistemi on-line di controllo, segue alcuni passi fondamentali come la formalizzazione e validazione dei dati acquisiti da sorgenti eterogenee esterne, la normalizzazione rispetto ai range di operatività, l’inferenziazione di cross-matching (inferentation-integration-data fusion), la de-normalizzazione dei risultati target ottenuti (v. Fig.).

Dal punto di vista concettuale, questo processo di modellazione della conoscenza è raffigurabile anche come una rete neurale artificiale costituita da “nodi” (neuroni) come unità base di elaborazione delle informazioni (Basic-Info) e “collegamenti” (sinapsi) come adduttori di inferenza caratterizzata da un grado di certezza (“peso” dinamico non probabilistico).
Modello DIKW della “Catena della Conoscenza”
Catena della Conoscenza: si tratta del primo principio sul quale si basa la struttura dei modelli di conoscenza, ovvero quello relativo alla Knowledge Chain DIKW (Data/Info/Knowledge/Wisdom), nella quale si distinguono i dati dalle informazioni e queste ultime dalla conoscenza, fino ad arrivare al concetto di saggezza.
-
- I dati sono definibili come entità statiche, “fotografie” di fatti e sono quindi espliciti, in genere sono espressi in forma alfanumerica, prodotti da fonti (database, sensori,…) che ne condizionano poi la loro “qualità”.
- Le informazioni sono entità dinamiche ed evolutive, caratterizzate da un proprio ciclo di vita, nascono in forma esplicita o latente, sono correlate ad uno o più processi (mentali, personali, ambientali, produttivi, ecc.) ed esercitano su tali processi una propria influenza (o “peso”).
Ad esempio: misurando la temperatura, la pressione atmosferica e l’umidità relativa esterna (dati), si ottiene un’informazione che può essere correlata all’abbigliamento da indossare (processo), condizionata dal “peso” che la stessa informazione ha su una determinata persona piuttosto che su un’altra e dura lo spazio temporale (ciclo di vita) limitato alla rispettive necessità di uscire da casa.
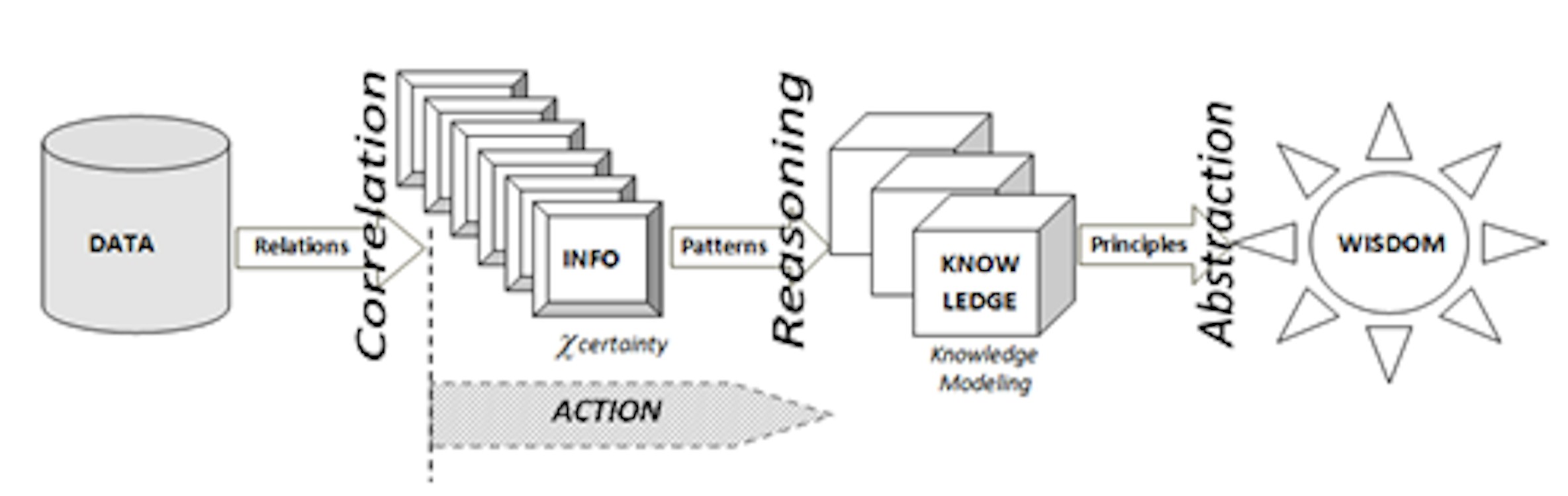
La Catena della Conoscenza DIKW
La catena della conoscenza DIKW non è solo un legame funzionale, ma esprime anche una azione: “ La conoscenza è informazione in azione“. Con riferimento al DIKW e alle precedenti considerazioni, si potrebbe quindi definire la conoscenza come la facoltà umana risultante dall’interpretazione delle informazioni finalizzata all’azione (Knowledge in Action), ovvero il risultato di un processo di inferenza e di sintesi (ragionamento), a partire da dati verso la saggezza (come ulteriore livello di astrazione dalla conoscenza acquisita).
Modello del “Valore dei Prodotti/Servizi”
Un modello di conoscenza non è necessariamente qualcosa di complicato, anzi può essere molto semplice, ad esempio se consideriamo la seguente espressione del Valore di un prodotto/servizio:

Se un prodotto/servizio fornisce le funzionalità f1+f2+f3, il costo di produzione corrispondente sarà c1+c2+c3 e pertanto:
- se si sbaglia a fornire una o più funzionalità fi perché non corrispondente a quanto richiesto o perché non necessaria, si avrà comunque un costo corrispondente ci e quindi, il Valore Vp sarà inferiore al dovuto: ciò esprime il concetto di Qualità del Prodotto/Servizio;
- se a parità di fi, riduco i costi ci dislocando l’azienda in paesi dell’estero ove è possibile farlo o acquistando materie prime più economiche il Valore Vp aumenta (virtualmente), ma dal momento che ci (al denominatore) può al limite tendere a zero, dopo di che il prodotto/servizio è perso inevitabilmente: ciò esprime il concetto di una Visione (suicida) di Cash-Flow di breve periodo del Prodotto/Servizio;
- solo migliorando e incrementando le fi, ovvero investendo in ricerca e innovazione si ha che il Valore si incrementa realmente (al limite all’infinito) ed è in grado di competere sul mercato: ciò esprime il concetto di una Visione (imprenditoriale) di medio-lungo periodo del Prodotto/Servizio;
Come è facile constatare, un semplice rapporto come quello sopraindicato esprime da solo, un modello di conoscenza che se fosse stato utilizzato dalla politica economica degli ultimi vent’anni, l’Italia oggi si troverebbe a competere con un rafforzato Made in Italy senza la necessità di svendere le aziende italiane e il patrimonio nazionale.
Come Potenziare le proprie Capacità di Sintesi Cognitiva e Abilità Decisionali, senza ricorrere a Coach, Mentor o Guru?
 Se consideriamo che l’unica certezza è l’incertezza, la cosa più naturale da fare è quella di convivere serenamente con quest’ultima. Siamo costretti allora a ricorrere ai tanti coach, mentor o guru disponibili sui “social-market” o ce la possiamo cavare autonomamente con un buon metodo e un po’ di sano buonsenso? Ma come? Beh, intanto c’è un primo punto da chiarire: esiste la possibilità di gestire” razionalmente o meglio, secondo logiche matematiche (quindi, non opinabili), l’incertezza insita in tutto quello che facciamo o pensiamo. Che significa? Se avessimo gli strumenti per gestire l’incertezza rendendola man mano “un po’ più certa”, risolveremmo diversi problemi… magari non immediatamente quello di avere più soldi in tasca, ma almeno quello di orientarsi nella direzione più sostenibile per noi, per ottenerli… E non è poco, se pensiamo ad es. che in un momento di crisi come quello attuale, la cosa più naturale e insensata è quella di “provare” in ogni direzione possibile, ritrovandosi dopo un pò allo stesso punto di partenza…
Se consideriamo che l’unica certezza è l’incertezza, la cosa più naturale da fare è quella di convivere serenamente con quest’ultima. Siamo costretti allora a ricorrere ai tanti coach, mentor o guru disponibili sui “social-market” o ce la possiamo cavare autonomamente con un buon metodo e un po’ di sano buonsenso? Ma come? Beh, intanto c’è un primo punto da chiarire: esiste la possibilità di gestire” razionalmente o meglio, secondo logiche matematiche (quindi, non opinabili), l’incertezza insita in tutto quello che facciamo o pensiamo. Che significa? Se avessimo gli strumenti per gestire l’incertezza rendendola man mano “un po’ più certa”, risolveremmo diversi problemi… magari non immediatamente quello di avere più soldi in tasca, ma almeno quello di orientarsi nella direzione più sostenibile per noi, per ottenerli… E non è poco, se pensiamo ad es. che in un momento di crisi come quello attuale, la cosa più naturale e insensata è quella di “provare” in ogni direzione possibile, ritrovandosi dopo un pò allo stesso punto di partenza…
La notizia non è che gli strumenti per gestire l’incertezza ci sono già ... (a questo proposito ho trovato molto intrigante l’articolo su l’intelligenza musicale per la formazione personale e professionale: Gestire l’incertezza: Strumenti e risorse per affrontare l’instabile presente), ma è che questi strumenti sono finalmente alla portata di tutti e tutti finalmente possono trarne vantaggio: dallo studente ventenne che deve scegliere il proprio percorso formativo professionale, al manager trentacinquenne che deve operare in contesti interdisciplinari e complessi, al quarantacinquenne che si trova a dover ricominciare un nuovo percorso di vita professionale (e non solo…).
Qual è la risposta alla domanda iniziale? La risposta “più vera” secondo me, è quella che è stata validata anche dall’esperienza (ventennale) sul campo e che in questo caso, può essere indicata come : sviluppo del Ragionamento Interdisciplinare per Modelli di Conoscenza noti (ITKS) ... E’ qualcosa di più semplice e “naturale” di quello che possa trasparire dai termini che lo descrivono. Il mio testo di riferimento è “Interdisciplinary Thinking by Knowledge Synthesis” (in Inglese con alcuni chiarimenti in Italiano), ma consiglio di non comprarlo (sarà regalato a chi vorrà approfondire l’argomento…) ed è scritto nella forma di raccolta di appunti delle lezioni utilizzate per la formazione dei miei collaboratori impiegati nella ricerca e innovazione industriale in ANOVA Lab.
La infosoluzione ITKS qui proposta è un programma auto-formativo di supporto suddiviso in 3 fasi:
- ITKS_intro: introduzione ai Modelli di Conoscenza ITKS per la Gestione dell’Incertezza.
- ITKS_base: introduzione agli Strumenti Logico-Matematici di Sintesi Cognitiva e Risoluzione della Complessità.
- ITKS_expert: sviluppo applicativo diSistemi di Monitoraggio Early Warning, Sistemi Esperti e di Supporto alle Decisioni.
Provare per credere!
.
“L’inconveniente delle persone e delle nazioni è la pigrizia nel cercare soluzioni e vie di uscita” (Albert Einstein)
________________________________________________________________
Per ricevere informazioni sui Corsi di Formazione compila il seguente Form (o contattami direttamente al +39.348.3366137 – g.mappa@anova.it):


Modelli di Conoscenza ITKS: come Utilizzarli, quali i Vantaggi
I Modelli di Conoscenza e il loro utilizzo
Per definire in maniera esaustiva il concetto di Modello di Conoscenza (Knowledge Model) bisognerebbe addentrarsi nei meandri delle Scienze Cognitive; per constatarne invece la loro utilità operativa e applicabilità pratica, l’ambito di riferimento è l’Ingegneria della Conoscenza: su questi argomenti esiste infatti un immenso patrimonio di letteratura tecnico-scientifica, a partire addirittura dagli anni ’50.
In termini generali, può essere sufficiente definire un Modello di Conoscenza come un algoritmo di “sintesi logico-matematica” in grado di inferenziare una moltitudine di dati/informazioni (input), per generare meta-informazioni (output) rispetto ad un target prefissato . In realtà, i modelli di conoscenza sono già a noi familiari da tempo e addirittura insiti nella nostra natura di esseri viventi in grado di osservare quanto ci circonda, interpretare tempestivamente gli eventi, gestire le incertezze e prendere delle decisioni di buon senso.
Infatti, tutti noi seguiamo dei modelli di riferimento che possono riguardare l’etica, la famiglia, la politica, ecc., come insieme di regole e valori condivisi e collaudati. Esempi tipici di modelli di conoscenza si ritrovano addirittura negli aforismi o nei proverbi, nati dall’esperienza e dalla saggezza popolare: ci aiutano in qualche modo a riflettere e a metterci in allerta (early warning) di fronte ad eventi di pertinenza.
Peraltro, nell’era in cui viviamo dell’Economia della Conoscenza e della ricerca dello sviluppo sostenibile, ciò si tradurrebbe da un lato, nella necessità di gestire la conoscenza secondo principi “tangibili” di economia, introducendo strumenti di misurazione del valore della conoscenza e dall’altro sviluppando un approccio sistematico e interdisciplinare alla risoluzione dei problemi. Tutto ciò si traduce nella necessità di gestire la conoscenza in maniera efficiente, ovvero in maniera tale da raggiungere gli obiettivi nel minor tempo e con la massima economicità, mentre ora sappiamo farlo già in maniera efficace e stiamo ancora imparando a farlo in maniera economica: Net-Economy, Big-Data, Green Energy, Smart City sono solo alcuni dei possibili contesti che ci richiamano il concetto di conoscenza efficiente.
I Modelli di Conoscenza ci aiutano a questo scopo: sono dei “Knowledge Pattern”, sintesi di regole già note o rese tali da opportuni procedimenti di estrazione di conoscenza (Data Mining /Knowledge Extraction), che forniscono le chiavi di lettura della complessità trasformandola in un sistema di knowledge pattern più semplici e sintetici. In altri termini, i modelli di conoscenza fungono da “scorciatoia” o da catalizzatori nei processi cognitivi per aumentarne l’efficienza. L’approccio dei Modelli di Conoscenza è stata presentato ufficialmente dall’autore della presente memoria per la prima volta nel 1993 a Palermo, in occasione del Congresso ANDIS, come sviluppo di un Sistema Esperto per la gestione dei processi biologici di depurazione delle acque, dimostrando come fosse possibile prevenire le anomalie di processo, incrociando i dati chimico-fisici di processo con le informazioni quali-quantitative relative al comportamento biologico (non-deterministico) dei microorganismi depurativi.
Un modello di conoscenza non è necessariamente qualcosa di complicato: vedi esempio del Modello del Valore dei Prodotti Servizi
Concetti e Principi Base
I Modelli di Conoscenza (Knowledge Models) sono quindi algoritmi che utilizzano il “linguaggio universale” della matematica per sviluppare in maniera quali-quantitativa sintesi di regole, di concetti e di scenari. Entrando più nel merito dell’argomento, è possibile enucleare alcuni concetti sui quali si basa applicazione della metodologia.
Risulta necessario infatti definire alcuni punti chiave:
- Catena della Conoscenza: si tratta del primo principio sul quale si basa la struttura dei modelli di conoscenza, ovvero quello relativo alla Knowledge Chain DIKW (Data/Info/Knowledge/Wisdom), nella quale si distinguono i dati dalle informazioni e queste ultime dalla conoscenza, fino ad arrivare al concetto di saggezza.
- Indipendenza Strutturale della Conoscenza dal contesto di riferimento: la struttura della conoscenza non è legata al peculiare ambito applicativo, ovvero: i processi di ragionamento fautori di conoscenza seguono dinamiche trasversali e interdisciplinari che sono ripetitive secondo classi tipologiche che fanno parte di un sistema inerziale nel quale valgono universalmente i principi base della Natura e dell’uomo (v. Piramide dei Bisogni Primari di A.Maslow), a prescindere dagli scenari tecnologici, politici e di mercato del momento.
- Propagazione del Grado di Certezza (vs Probabilità): se due o più informazioni input hanno un contenuto informativo inferenziale, eventualmente anche parziale o incerto a favore di una certa conclusione output, quest’ultima, frutto dell’intersezione ”insiemistica “ delle prime due, acquisirà un grado di certezza maggiore di quello contenuto in ciascuna delle informazioni di origine.
- Computazione Non-Deterministica: la computazione non deterministica ci consente di fare operazioni con le informazioni quali-quantitative anziché con i dati, ovvero con il contenuto informativo che i dati possono o meno esprimere.
- Modellazione Reticolare della Conoscenza: dal punto di vista logico, ogni modello di conoscenza è rappresentabile da una “cella informativa base” dotata di “n” dati/info in ingresso (input) e “m” meta-informazioni in output: all’interno della cella è possibile avere differenti relazioni di inferenza input/output: dalla semplice inferenza XY (curva di conoscenza n=1, m=1), fino a intere matrici “n*m” inferenziali. Gli “m” output di una cella possono a loro volta diventare in parte o in toto, input per un’altra cella e così via fino a realizzare una rete di celle in grado di elaborare un numero teoricamente infinito di informazioni.
Come Utilizzare i Modelli di Conoscenza:
- Sintesi Logico-Matematica di concetti chiave, complessi o interdisciplinari
- Modello di Simulazione Previsionale
- Modello Decisionale
- Computazione Non-Deterministica
- …
Quali i Vantaggi:
- Risolvere i Problemi Complessi in maniera più rapida ed economica
- Sviluppare Schemi di Ragionamento più Efficaci ed Efficienti: una marcia in più per molte professioni
- Sviluppare Innovazione di Processo mediante rielaborazione di Soluzioni già esistenti in altri campi
- Operare con entità intangibili (ad es. il Capitale Intellettuale) anche mediante l’utilizzo di sistemi informatici
- Sviluppare Modelli Dinamici di “Presa di Decisione”
- …
Esempi di Modelli di Conoscenza
Modelli Logico Matematici:
- Modello dell’Unità di Conoscenza: “Informazioni Elementari” e “Pattern” di Conoscenza
- Modello del Valore dei Prodotti/Servizi
- Modello del “Lavoro Competitivo”
- Modello Decisionale MQC
- Modello di Redditività del Business (Small Business)
- Modello di “Bussola del Business”
- Modello di Controllo Bilanciato del Business: Balanced Scorecard & Active Strategy Pilot Map
- …
Modelli Euristici:
- Modello DIKW della “Catena della Conoscenza”
- Modello dei “3 Cerchi”
- Modello della Comunicazione “Globale”
- Modello della Creatività e dell’Innovazione
- Modello del “Problem Solving”
- Modello del “Ragionamento Interdisciplinare”
- …
__________________________________________________
Per informazioni compilare il seguente Form:
Risparmio Energetico e Miglioramento Depurativo mediante controllo a “setpoint dinamico” dell’Ossigeno Disciolto: WDOxy Fuzzy
 Risparmio Costi di Gestione con WDOxy-Fuzzy Controller
Risparmio Costi di Gestione con WDOxy-Fuzzy Controller

Il Modello WDOxy Fuzzy è una procedura di calcolo real-time per il Set-Point Variabile dell’OD, ovvero della concentrazione di ossigeno disciolto necessaria per le effettive esigenze real-time del metabolismo batterico della rimozione del carbonio e dell’azoto.
La procedura WDOxy Fuzzy è stato sviluppato sulla base di algoritmi bio-processistici in “Logica Fuzzy” e sull’utilizzo in “input” della misura on-line del valore di concentrazione NH4 (in alternativa: ORP), oltre alla misura on-line dell’OD; restituisce in “output” in tempo reale, il valore di set-point ottimale di OD. WDOxy Fuzzy è applicabile sia a impianti biologici ad aerazione continuata che intermittente.
Concentrazione dell’Ossigeno Disciolto e Controllo Energetico: un controllo adeguato del funzionamento di un impianto di depurazione e in particolare, del reattore biologico (CSTR a “fanghi attivi” e con rimozione di N e P), si rende necessario sia per garantire la qualità dell’effluente e il rispetto dei limiti di legge, sia per contenere le spese di gestione: aspetto quest’ultimo che sta assumendo un’importanza sempre maggiore a causa dei crescenti costi dell’energia. Infatti, il controllo della fornitura di aria in un impianto a fanghi attivi è importante per le seguenti motivazioni:
- la fornitura di ossigeno è una delle principali voci di costo gestionali (10÷30 %);
- la fornitura di ossigeno è un fattore determinante per l’affidabilità della qualità dell’effluente depurato;
- la fornitura di ossigeno è un fattore determinante per l’efficienza della sedimentazione dei fanghi e dello stato di salute della biomassa.
Concentrazione dell’Ossigeno Disciolto e Bulking Filamentoso: la concentrazione dell’ossigeno disciolto (OD) nel reattore è un parametro di input di enorme importanza per la sua influenza sul bulking filamentoso e quindi, sulla sedimentabilità dei fanghi. La relazione tra il OD e lo SVI è direttamente influenzata dal carico organico (F/M): più elevato è il carico organico, più alta è la concentrazione di ossigeno disciolto necessaria per prevenire il bulking. La proliferazione di alcuni batteri filamentosi quali lo S.Natans, tipo 1701, e l’H. hydrossis in condizioni di basso ossigeno disciolto può essere attribuita all’elevata affinità (bassa costante di semisaturazione) che essi hanno per l’ossigeno.
Il controllo tradizionale con Set-Point Prefissato dell’ossigeno disciolto:
- Non si tiene conto della resa del processo di depurazione: necessaria la misura di un altro parametro (efficienza abbattimento NH4)
- Non si tiene conto della variabilità del carico entrante: si fornisce troppo o troppo poco ossigeno per la maggior parte del tempo
- Scarsa stabilità di controllo: i metodi di controllo tradizionali sono troppo semplificati e danno luogo ad instabilità

Vantaggi del sistema a Set-Point OD Dinamico WDOxy-Fuzzy rispetto al sistema tradizionale a Set-Point Prefissato:
- Risposta immediata a picchi entranti e condizioni di variabilità di carico entrante grazie ad un adattamento continuo del set-point di ossigeno disciolto: adattamento del processo biologico alle variazioni di carico in ingresso. Il sistema a set-point OD Dinamico, a differenza del sistema di controllo tradizionale (a set – point fisso di ossigeno disciolto) che evidenzia ampie oscillazioni, dimostra una notevole stabilità nel raggiungimento delle condizioni di processo ottimali, anche di fronte a significative variazioni del carico entrante
- Maggiore stabilità di processo ed efficienza depurativa, con particolare riferimento al processo di nitrificazione;
- Elevato risparmio energetico 15-20% e contestuale eliminazione degli eccessi di nitrificazione, in quanto viene evitata la fornitura di aria in eccesso ed ottenendo un miglior rendimento di trasferimento di ossigeno da parte dei diffusori.
- Assicura l’efficienza del rendimento di rimozione richiesto.
_________________________________________________________________________________
 Package di Acquisto WDOxy Fuzzy:
Package di Acquisto WDOxy Fuzzy:
- Software di Valutazione Dimensionamento/Configurazione
- Codice in Logica Fuzzy (PLC)
- Servizio di Assistenza Tecnica
Per ulteriori informazioni o quotazioni di offerta compila il form quì di seguito.
_________________________________________________________________________________
Esempio Applicativo WDOxy Fuzzy a Set-Point Dinamico:
Liquicontrol NDP

Liquicontrol NDP è un innovativo sistema di gestione e controllo dell’ossigeno disciolto in vasca d’aerazione e della concentrazione dell’azoto ammoniacale nell’effluente. Il valore di Azoto ammoniacale viene misurato in continuo, confrontato in tempo reale con il valore desiderato ed infine, utilizzato per il calcolo del set-point variabile dell’ossigeno disciolto. Il valore del set-point di ossigeno disciolto è poi confrontato con la misura dell’ossigeno disciolto presente in vasca in quel momento e determina, grazie ad una regolazione con logica fuzzy, l’erogazione dell’aria.
Brocure: Liquidcontrol NDP
Per la stima del risparmio energetico relativo al sistema Liquicontrol NDP, è possibile utilizzare un parametro denominato Indice di Prestazione ENergetica: rapporto tra l’energia attiva assorbita dal comparto di aerazione ed i più significativi carichi inquinanti rimossi, pesati secondo l’effettivo contributo alla fornitura d’aria:
IPEN = Energia (kWh/d) / [0,3*CODrimosso (kg/d)+0,7*NH4+rimosso(kg/d)]

![]()
Referenze in primo piano:
- Ottimizzare il Trattamento Acque – La Chimica & L’Industria – n.8 Ottobre 2012
- Ottimizzazione dell’Impianto di Depurazione Acque Reflue di Rimini (HERA SpA) – EnergiaAmbiente EA n.9 marzo 2013
- Ottimizzazione dell’Impianto di Depurazione Acque Reflue di Canone di Govone – Cuneo (SISI Srl) – Hi-Tech Ambiente n.6 – settembre 2013
__________________________________________________________________________________
Per ulteriori informazioni o quotazioni di offerta compila il form:
FENTON: Sistema Automatico di Controllo della “Compatibilità” dei Reflui Industriali e Speciali per il Trattamento Depurativo Biologico
La presenza di stazioni di pre-trattamento di reflui speciali sta diventando una consuetudine sempre più diffusa in molti degli impianti di depurazione di reflui urbani e di tipo misto, urbani e industriali (es.: a servizio di aree industriali, consorzi ASI, ecc.). Questa scelta è dettata evidentemente, da fattori soprattutto di tipo economico, dati i positivi riflessi sui bilanci gestionali degli stessi impianti. Tra i reflui che vengono in genere conferiti “su gomma” a detti impianti di depurazione, vi sono i percolati di discarica, gli spurghi di fosse settiche, reflui da aziende alimentari, tessili, della lavorazione dei metalli, grafiche, chimiche ecc. Il problema nella gestione dei reflui industriali e speciali è quello della “compatibilità” con il processo depurativo cui i reflui saranno sottoposti, considerando che in genere, trattasi di impianti di depurazione biologica e che ci sono dei limiti allo scarico finale da rispettare (v. D.lgs 152/1999 e succ. D.lgs 258/2000 art.36).
Vedere anche:
SWT-FNT: Modello di Calcolo/Verifica dei Pre-Trattamenti di Ossidazione Chimica FENTON per il Miglioramento della Biodegradabilità dei Liquami.
Controllo del Pre-Trattamento di Ossidazione Chimica:
FENTON Multidimensional Fuzzy-Model Control
Il processo FENTON è un trattamento di ossidazione chimica, che risponde alle esigenze di depurazione di reflui non trattabili biologicamente, quali ad esempio quelli altamente tossici o inorganici. Anova ha messo a punto un Sistema di Controllo Automatico dei Processi di Ossidazione Chimica FENTON basato fondamentalmente sulla misura real-time del pH, dell’ORP e del COD. La procedura adottata si basa sulla gestione ottimale del dosaggio di H2O2 e FeSO4 sulla base della tipologia di refluo in ingresso a condizioni di pH e temperatura ottimizzate.


La tecnologia Fenton si applica per il trattamento di diversi scarichi industriali contenenti composti organici tossici, quali fenoli, formaldeide, coloranti, pesticidi, additivi plastici, ecc. Essa si basa sulla elevata reattività del radicale ossidrile, che si forma in condizioni controllate di pH e temperatura, a partire da acqua ossigenata e ferro. Perché il trattamento si efficace e stabile, occorre in genere che il processo venga messo a punto con prove di laboratorio su campioni rappresentativi delle acque reflue da trattare.

_______________________________________
Per info:
