Modelli di Conoscenza come Catalizzatori di Efficienza Cognitiva e Strumento di Sviluppo di Sistemi Decisionali
_____________________________________________________________________________________________
I Modelli di Conoscenza e il loro utilizzo: per definire in maniera esaustiva il concetto di Modello di Conoscenza (Knowledge Model) bisognerebbe addentrarsi nei meandri delle Scienze Cognitive; per constatarne invece la loro utilità operativa e applicabilità pratica, l’ambito di riferimento è l’Ingegneria della Conoscenza: su questi argomenti esiste infatti un immenso patrimonio di letteratura tecnico-scientifica, a partire addirittura dagli anni ’50. In termini generali, può essere sufficiente affermare come un Modello di Conoscenza sia un algoritmo di “sintesi logico-matematica” in grado di elaborare (inferenziare) una moltitudine di dati/informazioni acquisiti come input da fonti esterne eterogenee, per restituire come output informazioni decisionali rispetto ad un target prefissato.
In questo contesto, si intende mettere in evidenza come i modelli di conoscenza siano già a noi familiari da tempo e addirittura insiti nella nostra natura di esseri viventi in grado di osservare quanto ci circonda, interpretare tempestivamente gli eventi, gestire le incertezze e prendere delle decisioni di buon senso. Infatti, tutti noi seguiamo dei modelli di riferimento che possono riguardare l’etica, la famiglia, la politica, ecc., come insieme di regole e valori condivisi e collaudati. Esempi tipici di modelli di conoscenza si ritrovano addirittura negli aforismi o nei proverbi, nati dall’esperienza e dalla saggezza popolare: ci aiutano in qualche modo a riflettere e a metterci in allerta (early warning) di fronte ad eventi di pertinenza.
Peraltro, nell’era in cui viviamo dell’Economia della Conoscenza e della ricerca dello sviluppo sostenibile, ciò si tradurrebbe da un lato, nella necessità di gestire la conoscenza secondo principi “tangibili” di economia, introducendo strumenti di misurazione del valore della conoscenza e dall’altro sviluppando un approccio sistematico e interdisciplinare alla risoluzione dei problemi. Tutto ciò si traduce nella necessità di gestire la conoscenza in maniera efficiente, ovvero in maniera tale da raggiungere gli obiettivi nel minor tempo e con la massima economicità, mentre ora sappiamo farlo già in maniera efficace e stiamo ancora imparando a farlo in maniera economica: Net-Economy, Big-Data, Green Energy, Smart City sono solo alcuni dei possibili contesti che ci richiamano il concetto di conoscenza efficiente [22][23][24][25]. I Modelli di Conoscenza ci aiutano a questo scopo: sono dei “Knowledge Pattern”, sintesi di regole già note o rese tali da opportuni procedimenti di estrazione di conoscenza (Data Mining /Knowledge Extraction), che forniscono le chiavi di lettura della complessità trasformandola in un sistema di knowledge pattern più semplici e sintetici. In altri termini, i modelli di conoscenza fungono da “scorciatoia” o da catalizzatori nei processi cognitivi per aumentarne l’efficienza. L’approccio dei Modelli di Conoscenza è stata presentato ufficialmente dall’autore della presente memoria per la prima volta nel 1993 a Palermo, in occasione del Congresso ANDIS, come sviluppo di un Sistema Esperto per la gestione dei processi biologici di depurazione delle acque, dimostrando come fosse possibile prevenire le anomalie di processo, incrociando i dati chimico-fisici di processo con le informazioni quali-quantitative relative al comportamento biologico (non-deterministico) dei microorganismi depurativi.
Un modello di conoscenza non è necessariamente qualcosa di complicato, anzi può essere molto semplice, ad esempio se consideriamo la seguente espressione del Valore di un prodotto/servizio:

Se un prodotto/servizio fornisce le funzionalità f1+f2+f3, il costo di produzione corrispondente sarà c1+c2+c3 e pertanto:
- se si sbaglia a fornire una o più funzionalità fi perché non corrispondente a quanto richiesto o perché non necessaria, si avrà comunque un costo corrispondente ci e quindi, il Valore Vp sarà inferiore al dovuto: ciò esprime il concetto di Qualità del Prodotto/Servizio;
- se a parità di fi, riduco i costi ci dislocando l’azienda in paesi dell’estero ove è possibile farlo o acquistando materie prime più economiche il Valore Vp aumenta (virtualmente), ma dal momento che ci (al denominatore) può al limite tendere a zero, dopo di che il prodotto/servizio è perso inevitabilmente: ciò esprime il concetto di una Visione (suicida) di Cash-Flow di breve periodo del Prodotto/Servizio;
- solo migliorando e incrementando le fi, ovvero investendo in ricerca e innovazione si ha che il Valore si incrementa realmente (al limite all’infinito) ed è in grado di competere sul mercato: ciò esprime il concetto di una Visione (imprenditoriale) di medio-lungo periodo del Prodotto/Servizio;
Come è facile constatare, un semplice rapporto come quello sopraindicato esprime da solo, un modello di conoscenza che se fosse stato utilizzato dalla politica economica degli ultimi vent’anni, l’Italia oggi si troverebbe a competere con un rafforzato Made in Italy senza la necessità di svendere le aziende italiane e il patrimonio nazionale [7].
Concetti e Principi Base: i Modelli di Conoscenza (Knowledge Models) sono quindi algoritmi che utilizzano il “linguaggio universale” della matematica per sviluppare in maniera quali-quantitativa sintesi di regole, di concetti e di scenari. Entrando più nel merito dell’argomento, è possibile enucleare alcuni concetti sui quali si basa applicazione della metodologia. Risulta necessario infatti definire alcuni punti chiave:
a) Catena della Conoscenza: si tratta del primo principio sul quale si basa la struttura dei modelli di conoscenza, ovvero quello relativo alla Knowledge Chain DIKW (Data/Info/Knowledge/Wisdom), nella quale si distinguono i dati dalle informazioni e queste ultime dalla conoscenza, fino ad arrivare al concetto di saggezza. I dati sono definibili come entità statiche, “fotografie” di fatti e sono quindi espliciti, in genere sono espressi in forma alfanumerica, prodotti da fonti (database, sensori,…) che ne condizionano poi la loro “qualità”. Le informazioni sono entità dinamiche ed evolutive, caratterizzate da un proprio ciclo di vita, nascono in forma esplicita o latente, sono correlate ad uno o più processi (mentali, personali, ambientali, produttivi, ecc.) ed esercitano su tali processi una propria influenza (o “peso”). Ad esempio: misurando la temperatura, la pressione atmosferica e l’umidità relativa esterna (dati), si ottiene un’informazione che può essere correlata all’abbigliamento da indossare (processo), condizionata dal “peso” che la stessa informazione ha su una determinata persona piuttosto che su un’altra e dura lo spazio temporale (ciclo di vita) limitato alla rispettive necessità di uscire da casa.
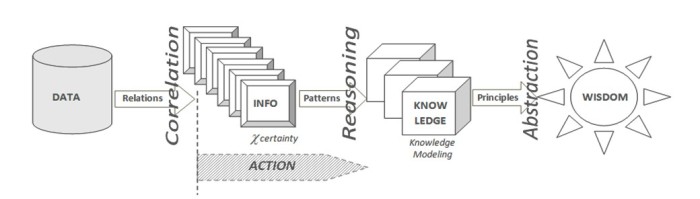
Fig.1 – La Catena della Conoscenza DIKW
La catena della conoscenza DIKW non è solo un legame funzionale, ma esprime anche una azione: “ La conoscenza è informazione in azione“[21]. Con riferimento al DIKW e alle precedenti considerazioni, si potrebbe quindi definire la conoscenza come la facoltà umana risultante dall’interpretazione delle informazioni finalizzata all’azione (Knowledge in Action), ovvero il risultato di un processo di inferenza e di sintesi (ragionamento), a partire da dati verso la saggezza (come ulteriore livello di astrazione dalla conoscenza acquisita).
b) Indipendenza Strutturale della Conoscenza dal contesto di riferimento: il principio base più innovativo è senza dubbio quello che esprime l’indipendenza della conoscenza dalla struttura lessicale e dal particolare glossario dei termini utilizzato: la struttura della conoscenza non è legata al peculiare ambito applicativo, ovvero: i processi di ragionamento fautori di conoscenza non sono “figli unici di madre vedova”, ma seguono dinamiche trasversali e interdisciplinari che sono ripetitive secondo classi tipologiche che fanno parte di un sistema inerziale nel quale valgono universalmente i principi base della Natura e dell’uomo (v. Piramide dei Bisogni Primari di A.Maslow [20]), a prescindere dagli scenari tecnologici, politici e di mercato del momento. Un esempio per tutti di indipendenza strutturale della conoscenza: l’Ingegneria Biomedica è nata quando finalmente discipline diverse dal punto di vista lessicale e dei contenuti, come la medicina, la fisica, l’ingegneria, la biologia, ecc., si sono incontrate “interdisciplinarmente” nel suddetto sistema di riferimento inerziale, al fine di soddisfare un bene primario come quello della salute. L’esistenza di una struttura comune della conoscenza consente un’interazione più facile con nuove aree di conoscenza e favorisce lo sviluppo dell’approccio di ragionamento interdisciplinare o “Interdisciplinary Thinking” [7], in quanto anche trovandosi in un contesto nuovo di conoscenza, è possibile riconoscere la struttura (comune) di ragionamento di riferimento e adattarsi velocemente allo specifico lessico e al glossario dei termini utilizzato e infine, essere in brevissimo tempo pro-attivi fornendo il proprio contributo cognitivo.
c) Propagazione del Grado di Certezza (vs Probabilità): altro principio fondamentale e distintivo dei modelli di conoscenza rispetto ad esempio, all’approccio statistico e probabilistico utilizzato normalmente nello sviluppo di strumenti inferenziali complessi come le ”Reti Bayesiane”, è che nella realtà industriale (e non solo) è poco frequente disporre di dati sufficientemente numerosi ed affidabili, nonché rappresentativi di un prefissato fenomeno in esame. Spesso viene confusa ad es. l’esistenza di un fenomeno con la frequenza con cui esso appare, fino a commettere l’errore di negarne l’esistenza soltanto perché “poco probabile”: è superfluo sottolineare come le catastrofi che puntualmente si verificano (in Italia e nel mondo) in occasione di ogni evento naturale “anomalo”, siano anche frutto di valutazioni a bassa probabilità… I modelli di conoscenza operano sulla propagazione della certezza, la quale si basa sul seguente concetto: se due o più informazioni input hanno un contenuto informativo inferenziale, eventualmente anche parziale o incerto a favore di una certa conclusione output, quest’ultima, frutto dell’intersezione ”insiemistica “ delle prime due, acquisirà un grado di certezza maggiore di quello contenuto in ciascuna delle informazioni di origine.
d) Computazione Non-Deterministica: i Modelli Matematici possono essere considerati come un particolare sottoinsieme dei Modelli di Conoscenza, ma mentre nei primi si rappresenta la realtà dei fenomeni secondo procedimenti deterministici e subordinata in genere a delle ipotesi iniziali semplificative, nei modelli di conoscenza la realtà è rappresentata anche nella propria natura non-deterministica, attraverso un approccio sistemico e procedimenti che tengono conto della “naturale” incertezza nei dati e nelle informazioni, rispetto alla minimizzazione degli errori e alla ricerca di soluzioni di “buon senso” (common sense). Poniamoci infatti, la seguente domanda: nel ragionare e prendere ad es. una decisione, il nostro cervello risolve un sistema di equazioni o risolve per caso un’espressione algebrica? Certo che no. Allora forse c’è un “gap” tra quello che ci hanno insegnato a scuola nell’ambito delle computazione di dati (v. Matematica) e il modo “naturale” di computare informazioni proprie del nostro cervello e poi trasferito alle macchine (v. Intelligenza Artificiale). La computazione non deterministica ci consente di fare operazioni con le informazioni quali-quantitative anziché con i dati, ovvero con il contenuto informativo che i dati possono o meno esprimere. Un dato può essere considerato come un “insieme” che ha un contenuto informativo percentualmente differente a seconda del contesto e del target a cui è destinato. Ritornando all’esempio precedente sulle condizioni atmosferiche, un valore di temperatura dell’aria esterna di 15 °C rispetto alla scelta di vestirsi in maniera adeguata per uscire di casa fornisce una indicazione decisionale solo parziale (% certezza), se non è sovrapposta alle altre informazioni come ad es. la pressione atmosferica e l’umidità relativa. L’insieme risultante dall’intersezione dei tre insiemi di partenza ottenibile rispetto ad un target di “tempo di pioggia” o di “tempo soleggiato”, fornisce un valore % risultante di certezza più elevato rispetto a quello che ciascun dato di partenza può esprimere singolarmente: se consideriamo che la temperatura di 15°C rispetto al target “meteo-pioggia”, contribuisce per il 30%, mentre la pressione atmosferica per il 25% e l’umidità relativa per il 35%, si avrebbe che la decisione di vestirsi in un certo modo piuttosto che in un altro avrebbe un grado di certezza complessivo del 65,875% (somma insiemistica), che è superiore al 50% di soglia, anche se con ancora un 34,125% di % incertezza che potrebbe essere soddisfatto da un’altra “intersezione insiemistica” fornito da un ulteriore dato (ad es. dal valore della velocità del vento). Alle stesse conclusioni si potrebbe arrivare con dati differenti (v. es. millimetri di pioggia), sia in termini di contenuto informativo che numerici.
e) Modellazione Reticolare della Conoscenza: dal punto di vista logico, ogni modello di conoscenza è rappresentabile da una “cella informativa base” dotata di “n” dati/info in ingresso (input) e “m” meta-informazioni in output: all’interno della cella è possibile avere differenti relazioni di inferenza input/output: dalla semplice inferenza XY (curva di conoscenza n=1, m=1), fino a intere matrici “n*m” inferenziali. Gli “m” output di una cella possono a loro volta diventare in parte o in toto, input per un’altra cella e così via fino a realizzare una rete di celle in grado di elaborare un numero teoricamente infinito di informazioni.
Un processo tipico di “modellazione” della conoscenza, soprattutto nella realizzazione di sistemi on-line di controllo, segue alcuni passi fondamentali come la formalizzazione e validazione dei dati acquisiti da sorgenti eterogenee esterne, la normalizzazione rispetto ai range di operatività, l’inferenziazione di cross-matching (inferentation-integration-data fusion), la de-normalizzazione dei risultati target ottenuti (v. Fig.2).

Fig.2 -Processo tipico di Modellizzazione della Conoscenza (Knowledge in Action)
Dal punto di vista concettuale [7], questo processo di modellazione della conoscenza è raffigurabile anche come una rete neurale artificiale costituita da “nodi” (neuroni) come unità base di elaborazione delle informazioni (Basic-Info) e “collegamenti” (sinapsi) come adduttori di inferenza caratterizzata da un grado di certezza (“peso” dinamico non probabilistico).
Grado di innovazione rispetto allo “Stato dell’Arte”: il grado di innovazione di questa metodologia rispetto allo “Stato dell’Arte”, risiede essenzialmente nei seguenti punti:
- rispetto alle Reti Neurali Artificiali (ANN) ogni nodo-neurone i-esimo è in grado di elaborare dinamicamente un numero elevato di input/output (multidimensionalità inferenziale), anziché un solo input/output con un’unica (e spesso statica), funzione di inferenza (attivazione);
- l’elaborazione inferenziale all’interno di ciascun nodo ha un adattamento continuo (apprendimento), ma rimane sempre “visibile”: è possibile in ogni momento ispezionare la configurazione di ciascun nodo della rete e dei relativi collegamenti-sinapsi, per cui il processo cognitivo è sempre tracciabile (cosa in genere non possibile nelle ANN);
- rispetto ai procedimenti statistico-probabilistici ed in particolare alle Reti Bayesiane, i Modelli di Conoscenza operano sul grado di certezza dei contenuti informativi, secondo un processo incrementale che ne riduce progressivamente l’errore, ottimizzando realisticamente il valore del processo cognitivo: ciò cambia totalmente il punto di vista rispetto al problema della disponibilità di dati storici e dei campioni statisticamente significativi, essendo in grado di utilizzare tutte le informazioni quantitative, qualitative o anche incerte di cui si è a disposizione, giungendo sempre ad una conclusione, con un livello di qualità ovviamente inversamente proporzionale alla stessa qualità degli input.
Campi di Applicazione: l’utilizzo di questi Modelli di Conoscenza offre diverse possibilità, con riferimento sia ai sistemi on-line/real-time e di Early-Warning (EWS), sia ove vi sia la necessità di supportare la diagnostica e la presa di decisione, particolarmente in situazioni caratterizzate da interdisciplinarietà, eterogeneità quantitativa e qualitativa dei dati, come ad es., nei processi ambientali, nella gestione dei processi industriali e addirittura, nella valutazione di beni intangibili come ad es. il valore della conoscenza stessa.
Lo spettro di azione dello sviluppo dei modelli di conoscenza è comunque molto ampio: a partire dai casi più semplici (2D) nei quali i modelli di riferimento (in questo caso “Curve di Conoscenza”) sono già noti ed esplici, ovvero i modelli sono impliciti e derivanti dall’elaborazione dati storici e dall’esperienza, fino a casi più complessi nei quali si hanno moltissime informazioni quanti-qualitativamente eterogenee derivanti da differenti sorgenti di dati (v. Big-Data), dove è necessario lo sviluppo di modelli di conoscenza del tipo Rete Neurali a Neuroni Esperti (v. Fig.2 XBASE tool, ANOVA).
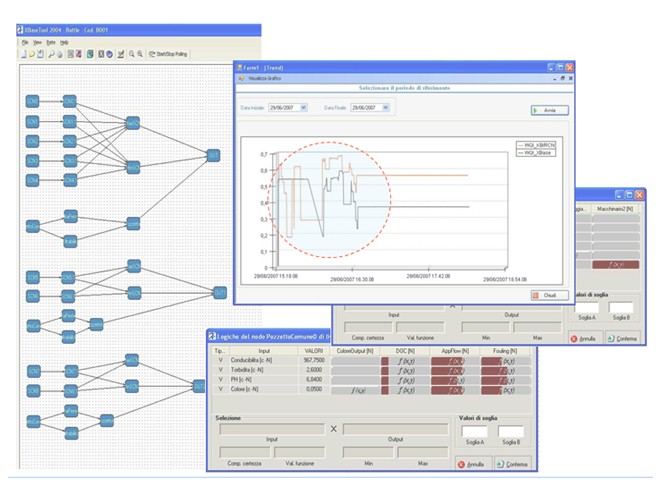
Fig.3 -Processo tipico di Modellizzazione della Conoscenza (ANOVA XBASE tool – Fig. da ENEA/BATTLE)
Le esperienze applicative dei modelli di conoscenza sviluppate dallo scrivente dal 1993 ad oggi, riguardano soprattutto l’ambito dei Sistemi Esperti di Supporto alle Decisioni, dei Sistemi on-line/real-time di Monitoraggio “Consapevole” e dei Sensori Software Intelligenti. In particolare, sono stati realizzati sistemi per:
- la rilevazione early-warning del rischio/credito;
- per il recupero di centri storici post-sisma;
- sistemi di controllo processo in ambito alimentare (mosto/vino, olio d’oliva EV, caseario),
- il monitoraggio on-line della qualità delle acque e del loro trattamento depurativo;
- il controllo early-warning degli Incendi boschivi e della salvaguardia ambientale;
- il monitoraggio early-warning degli odori molesti da impianti di trattamento rifiuti;
- il controllo energy saving di processi biologici;
- la gestione early-warning/predittiva della manutenzione di impianti industriali;
- diversi studi fattibilità operativa.
Note conclusive: si è presentata una metodologia sperimentata da parte dell’autore oramai nell’arco di un ventennio e che, nata per sviluppare sistemi basati sulla conoscenza (Knowledge Based System) e sistemi esperti di controllo, ha consentito una generalizzazione dell’approccio mentale rivelatasi molto utile nei processi decisionali. L’esperienza applicativa ha infatti mostrato la possibilità di considerare questa metodologia, oltre che uno strumento per rendere più performanti i sistemi informatici e di controllo automatico, anche come una vera e propria nuova “forma mentis” che consente di gestire la conoscenza in maniera interdisciplinare ed efficiente (Interdisciplinary Thinking)[7].
Conoscere per competere perché il futuro non è il prolungamento del passato…[7]
Bibliografia
- [1] Kendal, S.L.; Creen, M. (2007), An introduction to knowledge engineering, London: Springer, ISBN 9781846284755, OCLC 70987401
- [2] Jackson, Peter (1998), Introduction To Expert Systems (3 ed.), Addison Wesley, p. 2, ISBN 978-0-201-87686-4
- [3] Mohsen Kahani – “Expert System & Knowledge Engineering in Wikipedia” (2012)
- http://fumblog.um.ac.ir/gallery/435/Expert_System_Knowledge_Engineering_in_Wikipedia.pdf
- [4] Pejman Makhfi – “Introduction to Knowledge Modeling” (2013) – http://www.makhfi.com/KCM_intro.htm#What
- [5] Luca Console “Problem Solving Diagnostico: Evoluzione e Stato dell’Arte” – Dipartimento di Informatica – Università di Torino – AI*IA Notizie – Anno X n°3 Settembre 1997.
- [6] L. Console, P. Torasso: “Diagnostic Problem Solving: Combining Heuristic, Approximate and Causal Reasoning”, Van Nostrand Reinhold, 1989.
- [7] Giovanni Mappa “Interdisciplinary Thinking by Knowledge Sysnthesis” – IlMioLibro Editore (2011). http://ilmiolibro.kataweb.it/schedalibro.asp?id=647468
- [8] N. Brancati, G. Mappa (2009) “Capturing Knowledge in Real-Time ICT Systems to Boost Business Performance” ANOVA – Cognitive and Metacognitive Educational Systems: Papers from the AAAI Fall Symposium (FS-09-02)
- [9] Henrion, M. (1987). “Uncertainty in Artificial Intelligence: Is probability epistemologically and heuristically adequate?” In Mumpower, J., editor, Expert Judgment and Expert Systems, pages 105–130. Springer-Verlag, Berlin, Heidelberg.
- [10] G.Mappa ‐ “Distributed Intelligent Information System for Wastewater Management Efficiency Control” INFOWWATER‐ Wastewater Treatment Standards and Technologies to meet the Challenges of 21s t Century 4‐ 7th April 2000 AD – Queen’s Hotel, Leeds, UK ‐ 2000
- [11] G.Mappa, et Alii ‐ “Sistema di monitoraggio e gestione del trattamento delle acque cromiche” ‐ AI*IA99 – 6° Congresso della Associazione Italiana per l’Intelligenza Artificiale 7 Settembre 1999 ‐ Facoltà di Ingegneria– BOLOGNA ‐ 1999
- [12] EDILMED ‐ Convegno “Tecnologie Post‐Industriali trasferibili all’Architettura e all’Edilizia” ‐ Mostra d’Oltremare ‐19‐21 Maggio. Presentazione relazione su XBASEtool: “La Tecnologia dei Sistemi Esperti nell’Edilizia: Qualità Edilizia e Manutenzione Intelligente” ‐ G.Mappa‐ Napoli, 1995.
- [13] G. Mappa, R. Tagliaferri, D. Tortora – “On- line Monitoring based on Neural Fuzzy Techniques applied to existing hardware in Wastewater Treatment Plants” – AMSEISIS’ 97 – INTERNATIONAL SYMPOSIUM on INTELLIGENT SYSTEMS – September 12, 1997.
- [14] G. Mappa, G. Falivene, M. Meneganti, R. Tagliaferri – “Fuzzy Neural Networks for Function Approximation” – Proceedings of the 6th International Fuzzy Systems Association World Congress IFSA (1997).
- [15] G. Mappa – “Distributed Intelligent Information System for Wastewater Management Efficiency Control” – Wastewater Treatment Standards and Technologies to meet the Challenges of 21s t Century 4-7th April 2000 AD – Queen’s Hotel, Leeds, UK.
- [16] G. Mappa, G. Salvi, G. Tagliaferri, R. (1995) “A Fuzzy Neural Network for the On-Line Detection of B.O.D.” – Wirn Vietri ’95, VII Italian Workshop on Neural Nets ITALY.
- [17] G. Mappa, A. Sciarretta, S. Moroni e M. Allegretti (1993) “Sistema Esperto per la Gestione degli Impianti di Trattamento delle Acque Urbane” ‐ Congresso Biennale ANDIS’93 ‐ Palermo ‐ 21‐23 Settembre ‐Vol.II. ‐ 1993
- [18] “The Fractal Nature of Knowledge” Arnold Kling – Posted on December 4, 2008 by sethearley. http://sethearley.wordpress.com/2008/12/04/the-fractal-nature-of-knowledge/
- [19] Benoît B. Mandelbrot, Les objets fractals: forme, hasard et dimension, 1986
- [20] Abraham Harold Maslow, A Theory of Human Motivation, Psychological Review 50(4) (1943):370-96.
- [21] Carla O’Dell and C. Jackson Grayson, Jr. – “If Only We Knew What We Know,” Free Press, 1998.
- [22] http://www.conoscenzaefficiente.it/
- [23] http://waterenergyfood.net/2013/08/08/it-en-algoritmi-sullo-sviluppo-della-interdisciplinarieta-del-buonsenso-e-del-valore/
- [24] http://waterenergyfood.net/2013/06/10/il-valore-della-conoscenza-nellera-della-net-economy-2-parte/
- [25] http://waterenergyfood.net/2013/06/18/il-valore-della-conoscenza-nellera-della-net-economy-3-parte/

















