
Abbonati per continuare a leggere
Abbonati per ottenere l'accesso al resto di questo articolo e ad altri contenuti riservati agli abbonati.
Advisory inNOVAtion services
Abbonati per ottenere l'accesso al resto di questo articolo e ad altri contenuti riservati agli abbonati.
_____________________________________________________________________________________________
I Modelli di Conoscenza e il loro utilizzo: per definire in maniera esaustiva il concetto di Modello di Conoscenza (Knowledge Model) bisognerebbe addentrarsi nei meandri delle Scienze Cognitive; per constatarne invece la loro utilità operativa e applicabilità pratica, l’ambito di riferimento è l’Ingegneria della Conoscenza: su questi argomenti esiste infatti un immenso patrimonio di letteratura tecnico-scientifica, a partire addirittura dagli anni ’50. In termini generali, può essere sufficiente affermare come un Modello di Conoscenza sia un algoritmo di “sintesi logico-matematica” in grado di elaborare (inferenziare) una moltitudine di dati/informazioni acquisiti come input da fonti esterne eterogenee, per restituire come output informazioni decisionali rispetto ad un target prefissato.
In questo contesto, si intende mettere in evidenza come i modelli di conoscenza siano già a noi familiari da tempo e addirittura insiti nella nostra natura di esseri viventi in grado di osservare quanto ci circonda, interpretare tempestivamente gli eventi, gestire le incertezze e prendere delle decisioni di buon senso. Infatti, tutti noi seguiamo dei modelli di riferimento che possono riguardare l’etica, la famiglia, la politica, ecc., come insieme di regole e valori condivisi e collaudati. Esempi tipici di modelli di conoscenza si ritrovano addirittura negli aforismi o nei proverbi, nati dall’esperienza e dalla saggezza popolare: ci aiutano in qualche modo a riflettere e a metterci in allerta (early warning) di fronte ad eventi di pertinenza.
Peraltro, nell’era in cui viviamo dell’Economia della Conoscenza e della ricerca dello sviluppo sostenibile, ciò si tradurrebbe da un lato, nella necessità di gestire la conoscenza secondo principi “tangibili” di economia, introducendo strumenti di misurazione del valore della conoscenza e dall’altro sviluppando un approccio sistematico e interdisciplinare alla risoluzione dei problemi. Tutto ciò si traduce nella necessità di gestire la conoscenza in maniera efficiente, ovvero in maniera tale da raggiungere gli obiettivi nel minor tempo e con la massima economicità, mentre ora sappiamo farlo già in maniera efficace e stiamo ancora imparando a farlo in maniera economica: Net-Economy, Big-Data, Green Energy, Smart City sono solo alcuni dei possibili contesti che ci richiamano il concetto di conoscenza efficiente [22][23][24][25]. I Modelli di Conoscenza ci aiutano a questo scopo: sono dei “Knowledge Pattern”, sintesi di regole già note o rese tali da opportuni procedimenti di estrazione di conoscenza (Data Mining /Knowledge Extraction), che forniscono le chiavi di lettura della complessità trasformandola in un sistema di knowledge pattern più semplici e sintetici. In altri termini, i modelli di conoscenza fungono da “scorciatoia” o da catalizzatori nei processi cognitivi per aumentarne l’efficienza. L’approccio dei Modelli di Conoscenza è stata presentato ufficialmente dall’autore della presente memoria per la prima volta nel 1993 a Palermo, in occasione del Congresso ANDIS, come sviluppo di un Sistema Esperto per la gestione dei processi biologici di depurazione delle acque, dimostrando come fosse possibile prevenire le anomalie di processo, incrociando i dati chimico-fisici di processo con le informazioni quali-quantitative relative al comportamento biologico (non-deterministico) dei microorganismi depurativi.
Un modello di conoscenza non è necessariamente qualcosa di complicato, anzi può essere molto semplice, ad esempio se consideriamo la seguente espressione del Valore di un prodotto/servizio:

Se un prodotto/servizio fornisce le funzionalità f1+f2+f3, il costo di produzione corrispondente sarà c1+c2+c3 e pertanto:
Come è facile constatare, un semplice rapporto come quello sopraindicato esprime da solo, un modello di conoscenza che se fosse stato utilizzato dalla politica economica degli ultimi vent’anni, l’Italia oggi si troverebbe a competere con un rafforzato Made in Italy senza la necessità di svendere le aziende italiane e il patrimonio nazionale [7].
Concetti e Principi Base: i Modelli di Conoscenza (Knowledge Models) sono quindi algoritmi che utilizzano il “linguaggio universale” della matematica per sviluppare in maniera quali-quantitativa sintesi di regole, di concetti e di scenari. Entrando più nel merito dell’argomento, è possibile enucleare alcuni concetti sui quali si basa applicazione della metodologia. Risulta necessario infatti definire alcuni punti chiave:
a) Catena della Conoscenza: si tratta del primo principio sul quale si basa la struttura dei modelli di conoscenza, ovvero quello relativo alla Knowledge Chain DIKW (Data/Info/Knowledge/Wisdom), nella quale si distinguono i dati dalle informazioni e queste ultime dalla conoscenza, fino ad arrivare al concetto di saggezza. I dati sono definibili come entità statiche, “fotografie” di fatti e sono quindi espliciti, in genere sono espressi in forma alfanumerica, prodotti da fonti (database, sensori,…) che ne condizionano poi la loro “qualità”. Le informazioni sono entità dinamiche ed evolutive, caratterizzate da un proprio ciclo di vita, nascono in forma esplicita o latente, sono correlate ad uno o più processi (mentali, personali, ambientali, produttivi, ecc.) ed esercitano su tali processi una propria influenza (o “peso”). Ad esempio: misurando la temperatura, la pressione atmosferica e l’umidità relativa esterna (dati), si ottiene un’informazione che può essere correlata all’abbigliamento da indossare (processo), condizionata dal “peso” che la stessa informazione ha su una determinata persona piuttosto che su un’altra e dura lo spazio temporale (ciclo di vita) limitato alla rispettive necessità di uscire da casa.
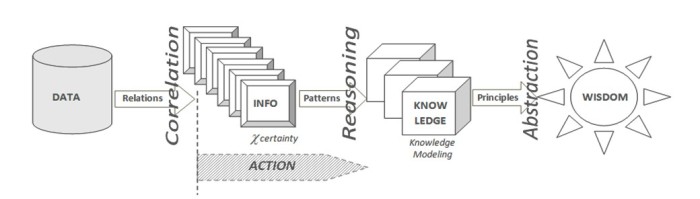
Fig.1 – La Catena della Conoscenza DIKW
La catena della conoscenza DIKW non è solo un legame funzionale, ma esprime anche una azione: “ La conoscenza è informazione in azione“[21]. Con riferimento al DIKW e alle precedenti considerazioni, si potrebbe quindi definire la conoscenza come la facoltà umana risultante dall’interpretazione delle informazioni finalizzata all’azione (Knowledge in Action), ovvero il risultato di un processo di inferenza e di sintesi (ragionamento), a partire da dati verso la saggezza (come ulteriore livello di astrazione dalla conoscenza acquisita).
b) Indipendenza Strutturale della Conoscenza dal contesto di riferimento: il principio base più innovativo è senza dubbio quello che esprime l’indipendenza della conoscenza dalla struttura lessicale e dal particolare glossario dei termini utilizzato: la struttura della conoscenza non è legata al peculiare ambito applicativo, ovvero: i processi di ragionamento fautori di conoscenza non sono “figli unici di madre vedova”, ma seguono dinamiche trasversali e interdisciplinari che sono ripetitive secondo classi tipologiche che fanno parte di un sistema inerziale nel quale valgono universalmente i principi base della Natura e dell’uomo (v. Piramide dei Bisogni Primari di A.Maslow [20]), a prescindere dagli scenari tecnologici, politici e di mercato del momento. Un esempio per tutti di indipendenza strutturale della conoscenza: l’Ingegneria Biomedica è nata quando finalmente discipline diverse dal punto di vista lessicale e dei contenuti, come la medicina, la fisica, l’ingegneria, la biologia, ecc., si sono incontrate “interdisciplinarmente” nel suddetto sistema di riferimento inerziale, al fine di soddisfare un bene primario come quello della salute. L’esistenza di una struttura comune della conoscenza consente un’interazione più facile con nuove aree di conoscenza e favorisce lo sviluppo dell’approccio di ragionamento interdisciplinare o “Interdisciplinary Thinking” [7], in quanto anche trovandosi in un contesto nuovo di conoscenza, è possibile riconoscere la struttura (comune) di ragionamento di riferimento e adattarsi velocemente allo specifico lessico e al glossario dei termini utilizzato e infine, essere in brevissimo tempo pro-attivi fornendo il proprio contributo cognitivo.
c) Propagazione del Grado di Certezza (vs Probabilità): altro principio fondamentale e distintivo dei modelli di conoscenza rispetto ad esempio, all’approccio statistico e probabilistico utilizzato normalmente nello sviluppo di strumenti inferenziali complessi come le ”Reti Bayesiane”, è che nella realtà industriale (e non solo) è poco frequente disporre di dati sufficientemente numerosi ed affidabili, nonché rappresentativi di un prefissato fenomeno in esame. Spesso viene confusa ad es. l’esistenza di un fenomeno con la frequenza con cui esso appare, fino a commettere l’errore di negarne l’esistenza soltanto perché “poco probabile”: è superfluo sottolineare come le catastrofi che puntualmente si verificano (in Italia e nel mondo) in occasione di ogni evento naturale “anomalo”, siano anche frutto di valutazioni a bassa probabilità… I modelli di conoscenza operano sulla propagazione della certezza, la quale si basa sul seguente concetto: se due o più informazioni input hanno un contenuto informativo inferenziale, eventualmente anche parziale o incerto a favore di una certa conclusione output, quest’ultima, frutto dell’intersezione ”insiemistica “ delle prime due, acquisirà un grado di certezza maggiore di quello contenuto in ciascuna delle informazioni di origine.
d) Computazione Non-Deterministica: i Modelli Matematici possono essere considerati come un particolare sottoinsieme dei Modelli di Conoscenza, ma mentre nei primi si rappresenta la realtà dei fenomeni secondo procedimenti deterministici e subordinata in genere a delle ipotesi iniziali semplificative, nei modelli di conoscenza la realtà è rappresentata anche nella propria natura non-deterministica, attraverso un approccio sistemico e procedimenti che tengono conto della “naturale” incertezza nei dati e nelle informazioni, rispetto alla minimizzazione degli errori e alla ricerca di soluzioni di “buon senso” (common sense). Poniamoci infatti, la seguente domanda: nel ragionare e prendere ad es. una decisione, il nostro cervello risolve un sistema di equazioni o risolve per caso un’espressione algebrica? Certo che no. Allora forse c’è un “gap” tra quello che ci hanno insegnato a scuola nell’ambito delle computazione di dati (v. Matematica) e il modo “naturale” di computare informazioni proprie del nostro cervello e poi trasferito alle macchine (v. Intelligenza Artificiale). La computazione non deterministica ci consente di fare operazioni con le informazioni quali-quantitative anziché con i dati, ovvero con il contenuto informativo che i dati possono o meno esprimere. Un dato può essere considerato come un “insieme” che ha un contenuto informativo percentualmente differente a seconda del contesto e del target a cui è destinato. Ritornando all’esempio precedente sulle condizioni atmosferiche, un valore di temperatura dell’aria esterna di 15 °C rispetto alla scelta di vestirsi in maniera adeguata per uscire di casa fornisce una indicazione decisionale solo parziale (% certezza), se non è sovrapposta alle altre informazioni come ad es. la pressione atmosferica e l’umidità relativa. L’insieme risultante dall’intersezione dei tre insiemi di partenza ottenibile rispetto ad un target di “tempo di pioggia” o di “tempo soleggiato”, fornisce un valore % risultante di certezza più elevato rispetto a quello che ciascun dato di partenza può esprimere singolarmente: se consideriamo che la temperatura di 15°C rispetto al target “meteo-pioggia”, contribuisce per il 30%, mentre la pressione atmosferica per il 25% e l’umidità relativa per il 35%, si avrebbe che la decisione di vestirsi in un certo modo piuttosto che in un altro avrebbe un grado di certezza complessivo del 65,875% (somma insiemistica), che è superiore al 50% di soglia, anche se con ancora un 34,125% di % incertezza che potrebbe essere soddisfatto da un’altra “intersezione insiemistica” fornito da un ulteriore dato (ad es. dal valore della velocità del vento). Alle stesse conclusioni si potrebbe arrivare con dati differenti (v. es. millimetri di pioggia), sia in termini di contenuto informativo che numerici.
e) Modellazione Reticolare della Conoscenza: dal punto di vista logico, ogni modello di conoscenza è rappresentabile da una “cella informativa base” dotata di “n” dati/info in ingresso (input) e “m” meta-informazioni in output: all’interno della cella è possibile avere differenti relazioni di inferenza input/output: dalla semplice inferenza XY (curva di conoscenza n=1, m=1), fino a intere matrici “n*m” inferenziali. Gli “m” output di una cella possono a loro volta diventare in parte o in toto, input per un’altra cella e così via fino a realizzare una rete di celle in grado di elaborare un numero teoricamente infinito di informazioni.
Un processo tipico di “modellazione” della conoscenza, soprattutto nella realizzazione di sistemi on-line di controllo, segue alcuni passi fondamentali come la formalizzazione e validazione dei dati acquisiti da sorgenti eterogenee esterne, la normalizzazione rispetto ai range di operatività, l’inferenziazione di cross-matching (inferentation-integration-data fusion), la de-normalizzazione dei risultati target ottenuti (v. Fig.2).

Fig.2 -Processo tipico di Modellizzazione della Conoscenza (Knowledge in Action)
Dal punto di vista concettuale [7], questo processo di modellazione della conoscenza è raffigurabile anche come una rete neurale artificiale costituita da “nodi” (neuroni) come unità base di elaborazione delle informazioni (Basic-Info) e “collegamenti” (sinapsi) come adduttori di inferenza caratterizzata da un grado di certezza (“peso” dinamico non probabilistico).
Grado di innovazione rispetto allo “Stato dell’Arte”: il grado di innovazione di questa metodologia rispetto allo “Stato dell’Arte”, risiede essenzialmente nei seguenti punti:
Campi di Applicazione: l’utilizzo di questi Modelli di Conoscenza offre diverse possibilità, con riferimento sia ai sistemi on-line/real-time e di Early-Warning (EWS), sia ove vi sia la necessità di supportare la diagnostica e la presa di decisione, particolarmente in situazioni caratterizzate da interdisciplinarietà, eterogeneità quantitativa e qualitativa dei dati, come ad es., nei processi ambientali, nella gestione dei processi industriali e addirittura, nella valutazione di beni intangibili come ad es. il valore della conoscenza stessa.
Lo spettro di azione dello sviluppo dei modelli di conoscenza è comunque molto ampio: a partire dai casi più semplici (2D) nei quali i modelli di riferimento (in questo caso “Curve di Conoscenza”) sono già noti ed esplici, ovvero i modelli sono impliciti e derivanti dall’elaborazione dati storici e dall’esperienza, fino a casi più complessi nei quali si hanno moltissime informazioni quanti-qualitativamente eterogenee derivanti da differenti sorgenti di dati (v. Big-Data), dove è necessario lo sviluppo di modelli di conoscenza del tipo Rete Neurali a Neuroni Esperti (v. Fig.2 XBASE tool, ANOVA).
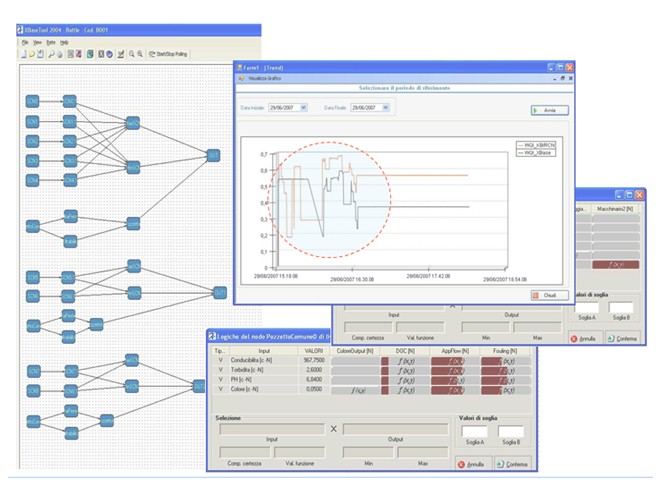
Fig.3 -Processo tipico di Modellizzazione della Conoscenza (ANOVA XBASE tool – Fig. da ENEA/BATTLE)
Le esperienze applicative dei modelli di conoscenza sviluppate dallo scrivente dal 1993 ad oggi, riguardano soprattutto l’ambito dei Sistemi Esperti di Supporto alle Decisioni, dei Sistemi on-line/real-time di Monitoraggio “Consapevole” e dei Sensori Software Intelligenti. In particolare, sono stati realizzati sistemi per:
Note conclusive: si è presentata una metodologia sperimentata da parte dell’autore oramai nell’arco di un ventennio e che, nata per sviluppare sistemi basati sulla conoscenza (Knowledge Based System) e sistemi esperti di controllo, ha consentito una generalizzazione dell’approccio mentale rivelatasi molto utile nei processi decisionali. L’esperienza applicativa ha infatti mostrato la possibilità di considerare questa metodologia, oltre che uno strumento per rendere più performanti i sistemi informatici e di controllo automatico, anche come una vera e propria nuova “forma mentis” che consente di gestire la conoscenza in maniera interdisciplinare ed efficiente (Interdisciplinary Thinking)[7].
Conoscere per competere perché il futuro non è il prolungamento del passato…[7]
Bibliografia
 METODOLOGIA DI APPROCCIO: Modelli di Conoscenza
METODOLOGIA DI APPROCCIO: Modelli di ConoscenzaLa scelta della metodologia dei “Modelli di Conoscenza”, nasce dall’esigenza di controllare e ottimizzare la funzionalità di un processo complesso che, specialmente se presenta una sezione “biologica” e input (carichi) variabili quali-quantitativamente nel tempo, non può essere assimilato ad un processo ciclico ripetitivo.
Pertanto, si sceglie in questi casi di non seguire un tradizionale approccio statistico (v. ANOVA– ANalysis Of VAriance), in quanto basato essenzialmente su dati storici e in genere molto costoso, preferendo un approccio più vicino agli esperti di processo, basato sulla “fusione” interdisciplinare tra dati rilevati e conoscenza degli esperti: i Modelli di Conoscenza.
Principi Base del Metodo basato sui Modelli di Conoscenza
a) Approccio Sistemico: realtà suddivisa in processi unitari (input/output), interagenti tra loro
b) Significatività e Rappresentatività delle Misure: è molto importante assicurarsi che i campioni oggetti di indagine siano realmente rappresentativi della realtà operativa o di classi di esse; pertanto le prove vanno eseguite definendo i parametri di caratterizzazione, come ad es.: Valore X = ¦[Xmin, Xmax, Xmed, X+freq, durata(X+freq)]
c) Modellazione delle Inferenze Input/Output: algoritmi di correlazione sistemica.
| CONFRONTO METODOLOGIE | PRO | CONTRO |
|
Modelli Statistici
|
|
|
| Modelli di Conoscenza |
|
|
Dott. Ing. Giovanni Mappa (rev. 2024)

Business Innovation Advisor (BIA)
Opero da diversi anni nell’ambito della ricerca e implementazione di soluzioni creative e innovative per le imprese, al fine di perseguire opportunità di crescita e promuovere e sviluppare contestualmente, la cultura dell’innovazione.
Gli aspetti caratterizzanti e distintivi del mio operato professionale sono:
– approccio interdisciplinare (interdisciplinary thinking) nel riconoscere le esigenze delle organizzazioni e nell’affrontare e risolvere i problemi che possono ostacolare la crescita dell’impresa;
– profonda conoscenza dei processi e del quadro normativo di riferimento per le attività rientranti nell’ambito della Ricerca Industriale (RI), dello Sviluppo Sperimentale (SS) e dell’Innovazione Tecnologica (AI, Blockchain, Monitoraggio Intelligente e Sistemi Knowledge Based), con particolare riferimento all’ammissibilità delle agevolazioni finanziarie e fiscali;
– attitudine all’operatività tempestiva pur nel contesto della visione e della missione strategica dell’impresa;
Ho maturato una consolidata esperienza in posizione di responsabilità nella gestione di rilevanti programmi e progetti (oltre 15 Mil.€) di innovazione tecnologica/trasformazione digitale e della divisione ICT presso aziende/gruppi societari di rilevante complessità organizzativa e funzionale, con strutture (RSI) dedicate alla trasformazione digitale e tecnologica.
STORIA PROFESSIONALE (II Fase: dal 2015 in poi)
Dal 1° feb. 2024 si presenta una nuova sfida in qualità di Business Innovation Advisor: gestire il cambiamento e sviluppare innovazione in una società cooperativa di ingegneria e lavori (WT eng.), operante nel settore del trattamento acque e rifiuti.


L’analisi del posizionamento strategico (Audit Tecnologico) dell’impresa WT eng. sul mercato, ha consentito di identificare le aree di miglioramento e le opportunità di innovazione che meglio rispondono alle necessità dell’azienda. L’analisi dettagliata delle dinamiche aziendali, con un focus specifico su innovazione, digitalizzazione, processi operativi, vendite e marketing, ha consentito un esame approfondito delle performance attuali e delle lacune da colmare rispetto ai concorrenti. L’analisi è stata condotta secondo il seguente modello:
___________________
Dal 2016 a fine 2023, ho ricoperto l’incarico di Responsabile Coordinatore dell’Area Ricerca Sviluppo e Innovazione (RSI) contemporaneamente per la società ARETHUSA Srl, operante nell’ambito dei Servizi Integrati di Ingegneria BIM e dell’Ingegneria di Manutenzione (Facility Management) e per la società NATURA Srl, società di servizi di analisi di laboratorio in ambito ambientale.



_________
Principali esperienze
_______________
Durante questo periodo ha avuto l’opportunità di frequentare corsi di specializzazione come “Teoria e Pratica di Project & Information Management nel Campo dell’Ingegneria” OICE Academy; Qualificazione e certificazione UnionCamere/MISE come “Manager dell’Innovazione”; Specializzazione Universitaria “BLOCKCHAIN FOR PROFESSIONAL AND BUSINESS SERVICE“– A.A. 2019/2020; Formazione APRE sull’utilizzo di strumenti di Finanza Agevolataregionali, nazionali ed europei (rif.: Horizon Europe/ EIC Accelerator e Pathfinder) ed altri corsi di formazione professionale e di aggiornamento.





_______________
STORIA PROFESSIONALE (I Fase: 1985-2014)
Laureato in Ingegneria Meccanica/Impianti nel 1985 presso il Politecnico di Bari.

Vincitore nel 1996 di una Borsa di Studio nell’ambito della selezione a livello nazionale di neolaureati da inserire nell’ambito della Ricerca e Sviluppo e Innovazione Industriale (FINSIDER), presso il CSM (Centro Sperimentale Materiali [Ing. M. Ghersi – Ing G. Todarello) a Roma. Il periodo di formazione è durato circa un anno e si è poi concluso con successo.

_____________________

Dal 1987 al 1991, ha vissuto una intensa esperienza da progettista e da responsabile di progetto (con procura alla firma) nella società di ingegneria ITALIMPIANTI SpA (Gruppo IRI) di Genova, dove ha svolto in particolare, attività di progettazione, coordinamento e assistenza al cantiere per la realizzazione di impianti tecnologici e reti metano.

______________
Nel 1992, entro come ricercatore nel Consorzio SESPIM di Ricerca per le Applicazioni Reali dell’Intelligenza Artificiale (ALENIA, ITALIMPIANTI) con sede a Napoli. Qui ho l’opportunità di acquisire una formazione specifica nell’ambito applicativo delle tecnologie ICT e dell’Intelligenza Artificiale, delle metodologie dell’Ingegneria della Conoscenza (Data Analytics, Machine Learning, Knowledge Exstraction) all’interno del Consorzio di Ricerca SESPIM (5 anni) [vari docenti dell’UNISA tra cui: Vincenzo Loia – Prof. Roberto Tagliaferri].

Nel 1994 sempre in SESPIM assume il ruolo di coordinatore di progetti di ricerca riguardanti il settore dei Sistemi Esperti real-time per applicazioni ambientali (S.C.E.T.T.R.O.) e il settore della sensoristica intelligente (Soff-Sensors, Virtual Sensors). Inoltre, ho l’opportunità di formarmi sulle metodologie di gestione del Capitale Intellettuale (Intangibles IPR) per lo sviluppo delle opportunità di business, nell’ambito della R&S e dello sviluppo di nuovi prodotti/servizi. Metodologie per la Gestione degli Intangibles, per lo sviluppo delle Opportunità di Business. [docente: ssa Annie Brooking in ALENIA).
______________
Nel 1997, con un’operazione di “Spin-Off” dal SESPIM, fonda ANOVAstudi.com: una società privata di ricerca industriale, di servizi interdisciplinari di ICT e di Intelligenza Artificiale.


Dal 1998 al 2002 assume il ruolo di consigliere nel Direttivo Nazionale AI*IA Associazione Italiana per l’Intelligenza Artificiale con sede a Milano. Nello stesso periodo, assume la carica di vice-presidente nel Consorzio di Ricerca ENEA/TERRI – “Consorzio per lo Sviluppo e il Trasferimento di Tecnologie di Recupero e Riciclo di Residui Industriali” – presso il Centro Ricerche ENEA della Trisaia a Rotondella (MT).


Nel 2004 ottiene, per la società ANOVAstudi.com, la certificazione di Laboratorio di Ricerca Industriale MIUR (Ministero dell’istruzione, dell’università e della ricerca), impiegando 15 giovani ricercatori e operando nell’ambito dei Sistemi ICT e Sistemi Esperti per il “mercato libero” della ricerca industriale per le imprese (PMI). Responsabile del Laboratorio R&S ANOVA(Novembre 1997 – in corso) – ANOVA (Centro Direzionale, is.G1/c Napoli, (Lab. ANOVA) http://albolaboratori.miur.it/Regione.aspx?LabCat=306).
Dal 2007 al 2010, assume la carica di direttore tecnico-scientifico della società olandese SENSOR Intelligence B.V. presso la sede di Leeuwarden (NL), operante nelle applicazioni di sensori intelligenti software e nel controllo avanzato di processo (APC) con clienti olandesi tra cui la multinazionale Friesland Food.







____________

2014 Riconoscimento “Nella Valigia dei Talenti ″ a cura dell’Ass. Agorà e Comune di Crispiano (TA) – consegnato all’Ing. Giovanni Mappa (Fondatore di ANOVA) il 13 Luglio 2014 dall’Ing. Angelo Michele VINCI – Cavaliere del Lavoro e Presidente di Confindustria Bari-BAT
Fine della I Fase del mio sviluppo professionale (1985-2014)


____________________
Altri progetti di rilievo realizzati come ANOVA:
Autore di diversi Brevetti e Copyright fra i quali:
Autore di una quarantina di Pubblicazioni Tecnico-Scientifiche tra cui:
Competenze
Tra le principali attività di R&S per lo sviluppo di progetti di innovazione ed esperienze professionali specifiche sulle tecnologie impresa 4.0, vengono riportati i seguenti:
Altri incarichi ANOVA per lo sviluppo e la gestione di progetti di innovazione basati su finanza agevolata:
___________________
Documentazione di supporto
Corso di Perfezionamento universitario “Blockchain for professional and business services” dell’Università degli Studi di Napoli “Parthenope” – Dipartimento di Studi Aziendali ed Economici (DISAE). Anno Accademico 2019/2020 – Dipartimento di Studi Aziendali ed Economici (DISAE) dell’Università degli Studi di Napoli “Parthenope”.
ici:
Articoli specialistici:
Principali Pubblicazioni Scientifiche:
 http://www.h2biz.eu/scheda_prodotto.asp?prod=2079
http://www.h2biz.eu/scheda_prodotto.asp?prod=2079
Formazione e Trasferimento Tecnologico per l’acquisizione degli Strumenti Logico – Matematici dell’approccio interdisciplinare I.T.K.S. (Interdisciplinary Thinking by Knowledge Synthesis).
Si tratta di una metodologia che aiuta notevolmente a risolvere la complessità dei problemi professionali, attraverso il riconoscimento e/o l’utilizzo di “Modelli di Conoscenza”. Questi ultimi, possono essere assimilati a strutture canoniche di Conoscenza (esplicita o implicita), il cui riconoscimento appunto, consente di risolvere più rapidamente e facilmente, i vari “puzzle” che si incontrano generalmente nei processi di problem – solving e presa di decisione, nonché nell’ambito dello sviluppo dell’innovazione di processo.
La metodologia I.T.K.S. nasce agli inizi degli anni ’90 come “motore inferenziale” di sintesi logico – matematica ed è utilizzato per lo sviluppo informatico di Sistemi Esperti ES e di Supporto alle Decisioni DSS (Intelligenza Artificiale).
Dall’esperienza applicativa informatica e da quella relativa alla formazione del personale addetto, si è venuto a creare un vero e proprio approccio cognitivo interdisciplinare, trasferibile ai diversi profili professionali emergenti e “Knowledge Intensive”.
La vera innovazione nella metodologia I.T.K.S. risiede soprattutto nel concetto di “indipendenza della struttura della Conoscenza” dal contesto (lessicale) in cui si sviluppa, nonché nella possibilità di “modellare” con linguaggio universale logico – matematico “porzioni” di Conoscenza ricorrente con Modelli di diverso tipo, derivanti ad es. dalla esperienza popolare, fino alle leggi più rigorose della Fisica o dell’Economia, ecc. Detta possibilità, oltre a fornire l’indubbio vantaggio di riuscire a ”capitalizzare” la conoscenza, funge da catalizzatore nei processi cognitivi (sia umani che informatici), nel senso che consente di generare le conclusioni più valide nel minor tempo.
L’utilizzo applicativo dei Modelli di Conoscenza come già detto, ricopre una casistica molto ampia, fino allo sviluppo di sistemi on – line/real – time e di early – warning, nonché ove vi sia la necessità di prendere delle decisioni, in situazioni caratterizzate da elevata eterogeneità quantitativa e qualitativa dei dati come ad es., nei processi ambientali, nella gestione dei processi industriali e addirittura, nella valutazione di beni intangibili (ad es. il valore stesso della conoscenza).
Come Potenziare le proprie Capacità di Sintesi Cognitiva e Abilità Decisionali, senza ricorrere a Coach, Mentor o Guru?
________________________________
Per la frequentazione del Corso ITKS è preferibile possedere una base formativa scientifica anche scolastica (nell’ambito delle Scienze Matematiche, Fisiche e Naturali, ovvero nell’ambito delle Scienze Economiche e Statistiche).
Per Info:
 Interdisciplinary Thinking by Knowledge Synthesis
Interdisciplinary Thinking by Knowledge Synthesis
(2011) In un mercato del lavoro contraddittorio e imprevedibile come quello attuale, nel quale le professionalità “medie” (“colletti bianchi”) sono sempre meno richieste, a favore di un dicotomico interesse per la categoria degli artigiani (cuochi, panettieri, ecc.) da una parte, emergenti professionalità “Knowledge Intensive” dall’altra. Queste ultime, frutto della globalizzazione della conoscenza, sono caratterizzate da una crescente competitività in termini di flessibilità e interdisciplinarità. La sfida da affrontare è il lavoro che manca, perché per decenni si è puntato solo alla riduzione dei costi, piuttosto che alla creazione di valore ed eliminazione degli sprechi. La sfida da affrontare è il lavoro che cambia, sia in termini temporali, che in termini concettuali: se è cambiata la domanda, l’offerta dovrà necessariamente adeguarsi.
“Non possiamo pretendere che le cose cambino, se continuiamo a fare sempre le stesse cose...” (A. Einstein). Il presente lavoro intende contribuire a dare possibili risposte alle seguenti domande:
La soluzione proposta in questi libro di appunti è l’apprendimento del “ragionamento interdisciplinare” (v. http://www.conoscenzaefficiente.it) e la metodologia proposta, nelle sue linee essenziali, si basa sul concetto dell’esistenza una struttura comune e ricorrente della conoscenza (Knowledge’s Common Frame) che, con le sue proprietà e dinamiche evolutive, rappresenta la “chiave di volta” del nuovo approccio. Pur contenendo algoritmi di tipo matematico, il testo segue un filo logico discorsivo che lo rende adatto a lettori con un “background” non solo di tipo tecnico-scientifico, ma anche economico-gestionale e politico.
Il libro è scritto in un inglese tecnico, ma contiene note e commenti in Italiano. Due casi applicativi della metodologia, come l’Interdisciplinary Knowledge Worker e il K-commerce, sono riportati ad esempio.
Something old, something new, something better…, perhaps something for you.


